This post continues our look at using metadata effectively: we’ll talk about making a metadata governance document and building a prototype.
If you are in charge of a corporate or institutional media library, I strongly suggest that you consider making a metadata planning or policy document, also called a governance document. Once you’ve done that, you’ll want to do some proof-of-concept testing to verify your assumptions. I’ve assisted a number of companies in this exercise, and it helps in several ways:
- It helps the collection manager(s) think clearly about what metadata will be helpful and how to structure it.
- It helps to make sure other people in the group can agree on what’s going to be useful.
- It helps to standardize how metadata is used, when more than one person is doing the tagging.
- It preserves the meaning of the tags into the future, even when there is a personnel change.
- It helps to evaluate what software to use, and how to scope implementation projects.
- It gives you some tools for internal testing--a a place to record and validate assumptions (or make a note that you will need to rethink something).
Many of the points above can be summarized as “it gets the metadata process out of one person’s head and in front of other people.”
What goes into a policy document
I’ll list out the way I like to structure metadata policy documents. You can modify this to suit the needs of your collection or your organization. The example shown below is a general media library. If you are working in an area where there is a mature schema, such as a museum, then you’ll want to start your planning by referring to that schema.
In the following images you’ll find a sample starter document that shows you a scope and structure for your own document.
You can download this document to use as a template here.


Top line items
Let’s start the discussion with a set of objectives and parameters. As with much of this exercise, don’t be afraid to list out stuff that may seem obvious. It’s common for people to make incorrect assumptions about how others think. This is particularly true if the team includes people who have never built a collection before.
- A list of goals - We start with the most obvious stuff: what is the collection, who are the stakeholders, and what are the goals in building and using the collection? Having these written down at the outset can help you evaluate all your decisions in light of the entire stakeholder group.
- Roles and responsibilities - Building and managing a media library does not happen all by itself. It’s essential to outline who will be working on the project and what they will be in charge of. This is usually essential for budgeting and reality-checking. By outlining this, you can prevent holes in the workflow that don’t fall into anyone’s area of responsibility.
- A list of fields you need - Now we start to build a taxonomy. I suggest making a list of what’s important to you, dividing it into categories for administrative, descriptive, technical, and curatorial fields. At the start of the process, you can be over-inclusive. We’ll have a chance to pull back later. Also, I suggest that you approach this as an ideal list, even if it’s not practical with your current software. You may find that your current needs far exceed the capabilities of the current software, or maybe you will see a need for software migration out on the horizon.
Testing your work
Creating a metadata policy is almost certainly going to be an iterative process. You’ll need to start with some assumptions of what information is valuable, and then try to validate those assumptions. Instead of simply discussing metadata, I suggest that you make a proof-of-concept using actual media from your collection. This can be used as a test of the entire approach to discoverability. The following is how I’ve done it with institutional clients.
Testing
Here are some steps for testing your assumptions:
- Start with a policy document that lists out the metadata we think will be useful.
- Identify a representative sample of files from the collection. This might be 200 to 2000 files, covering a broad array of the subject matter in the collection.
- Build out a sample collection in some type of software that allows you to configure and reconfigure, adding the metadata you have identified in the document.
- Ask sample users if they can find what they need. By watching how the users behave, you can see if you’ve made good assumptions.
How can I build the test?
One of the hardest parts of the exercise is the creation of a sample library for testing. Many enterprise applications require a full-fledged configuration (and a lot of money) for you to build out a sample.
It is possible to build your sample with desktop software quickly and cheaply. Lightroom does a great job with photo-centric collections, but there are not a lot of great options for collections that include multiple non-photo file types. And using desktop applications for this type of testing is not ideal, since it does not replicate what the stakeholder user experience is going to be.
MediaGraph to the rescue
One of our objectives with MediaGraph 3 (MediaGraph) is to fill the holes in the software ecosystem--easily prototyping your metadata policy is one such hole. We’ve built MediaGraph so that you can easily configure and reconfigure your taxonomy, rights packages, browsable hierarchy and more. Put it in front of your co-workers right away, and make sure it works. Tweak the parts that need tweaking. Go live as you see that you’ve got it right. We think it’s the fastest, easiest way to validate your assumptions, and build the system your stakeholders need.
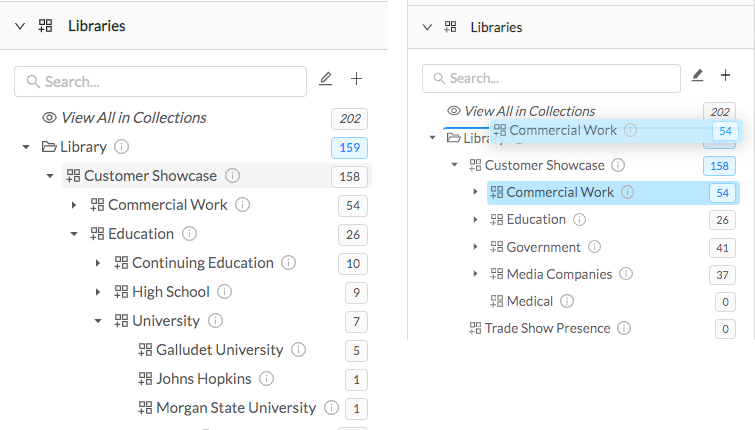
MediaGraph allows you to build a hierarchy of collections and easily rearrange them or rename them. Build a prototype, and see how your stakeholders understand the structure. Rename and reconfigure to make it more intuitive.
You have the same total flexibility to configure and optimize your taxonomies in MediaGraph. Build, test on stakeholders, and improve based on feedback.