Let’s also classify metadata by how it is created, since that determines the “cost” of the metadata. Metadata can be generated in ways that range from highly automated to highly manual. Here are the categories.
Automatically created metadata
The first kind of metadata we will look at is information that is created without any input from you. There are two types of automatically generated metadata: file properties and device-created metadata.
File properties
The file properties (also called media information) are the most basic pieces of information about your files. File properties include a file’s size, format, creation date, encoding and other file characteristics. You can see a basic metadata properties screen in the figure below. This information is essential for applications to be able to correctly render your media, and it is typically not user-editable. This information is also useful for general file identification and management. For instance, you can compare sizes to see which copy of a file has a higher resolution or you can compare file modification dates to see which is more recent.
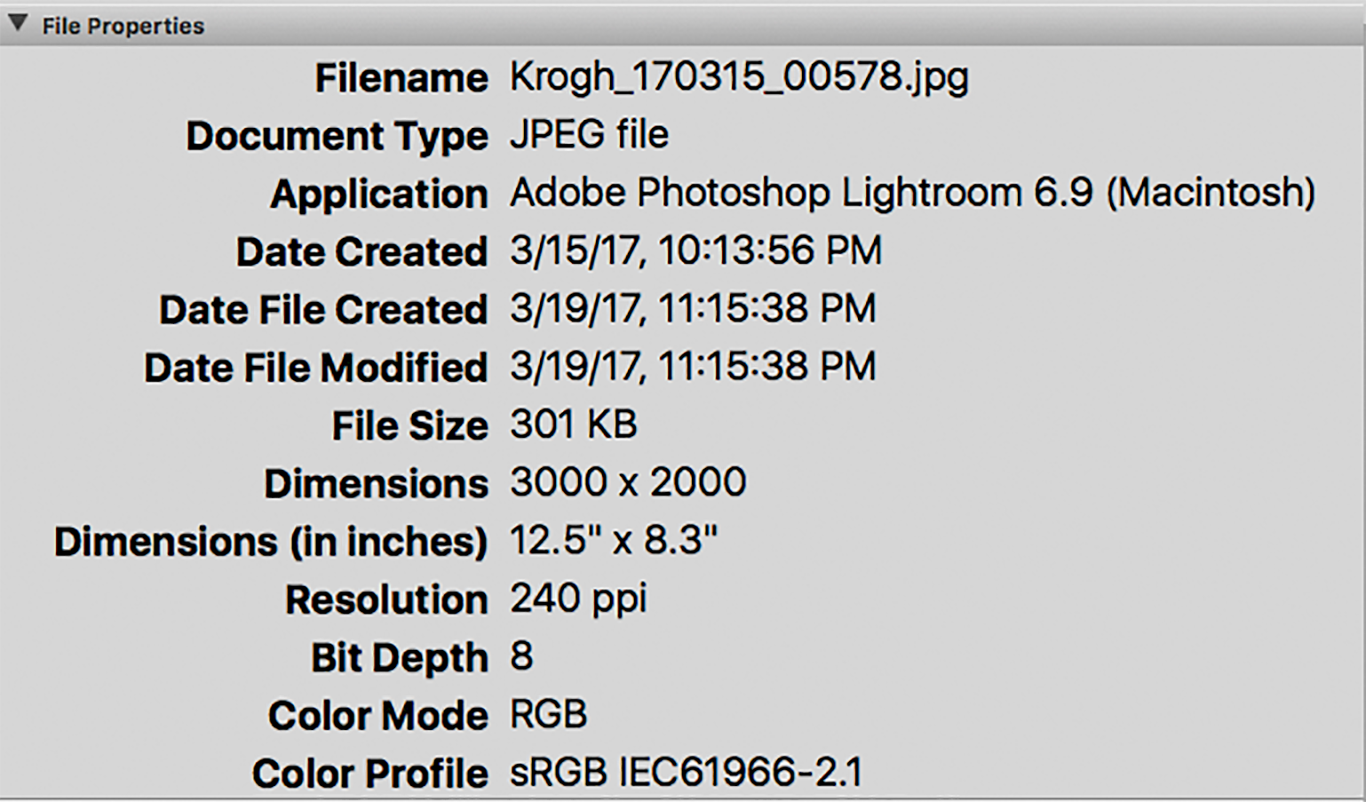
Here is the metadata panel from Adobe Bridge, showing file properties. This is not a complete list of the file properties, but it does show many of the important ones for image files.
Device-created information
Here is the EXIF panel from Adobe Bridge. Because each camera manufacturer writes EXIF data slightly differently, you may not see exactly the same fields in your EXIF panel. This figure represents less than a quarter of the actual EXIF fields.
Another type of automatically generated metadata is the information that the device creates when it creates a photo, video or other media item. This information is embedded into the image file and you can use it to organize images in some useful ways. Date tags (if they exist) are incredibly useful for filtering and making use of images. Information about the camera, such as make, model and serial number can provide important clues to the origination of images. And shooting data like ISO, lens, and f-stop can also be useful in certain circumstances. This is all written to the file in the form of EXIF data, which we’ll look at in more depth in another post.
Most smartphones and a growing number of cameras can record Global Positioning System (GPS) coordinates at the time of capture. We’ll take a longer look at GPS later in this chapter. Cameras can also record proprietary information to the image files in the form of private maker notes. The camera manufacturer’s software can use this information for post-processing automation. Sometimes third-party applications such as Photoshop can decode the private maker notes, and sometimes the data is written in such a way that it can’t be decoded by anyone except the manufacturer.
Some cameras also allow you to enter information about you, the photographer, or even information for a specific shoot. The basic functionality includes a copyright statement, and in some cases can include a substantial number of IPTC fields.
Bulk-entry data
Next we move into the category of user-supplied information: data that is not automatically generated and must be entered by hand. The most basic is bulk entry data which you can apply to many images at once.
Bulk entry data could include information such as the photographer’s name and contact information, the name of the subject, the location where the photographs were made, the client’s name, and other characteristics that don’t involve the evaluation of individual photos.
Entering bulk metadata is quick and can provide a very good return on the time invested. I suggest that all bulk entry information be recorded for digital originals at the point of ingestion, whenever practical. I define “practical” as information that can be applied to all images as a group. Sometimes the only information common to all images will be the photographer name and contact info. Sometimes an entire card or download may be from a single shoot or group of shoots that share many characteristics in common. Whatever tags you can add to an entire group of images, you should add to the entire shoot.
Here are some of the options for bulk metadata entry:
- Name and contact information of photographer
- Location where photograph was taken, when practical. Be as specific as possible for the entire group of images.
- Broad classification of images (e.g., “Personal Work” or “Jobs”)
- Original intended use, if applicable (e.g., “Personal Work,” “Assignment Name,” or “Stock”)
- Name of people or subjects pictured (when practical)
- General project keyword(s) (e.g., “Vacation,” “Magazine Story X,” “Brochure Job Y”)
- Client name, if any
- License agreement, if any
You can typically enter this information in a matter of seconds, even for hundreds of images. Most often, you’ll do so by means of a metadata template, a saved set of tags that you can apply to many images at once. You can create and save templates in almost all image-editing or DAM software.
Using metadata templates can save you lots of time. Here’s the one from Photo Mechanic, which is generally considered to be the most comprehensive tool for tagging incoming image files.
Computational tagging
Metadata can also be created by computational tagging tools. This can consist of machine learning, Artificial Intelligence or by using linked data.
Some of this may be done at the time of capture, if you are shooting with a smartphone or other web-connected camera.
This can also be done through some library software or services that send images on a round-trip through a tagging service.
And some applications may offer black box tagging, where the files are continually evaluated to add, remove or refine tags.
Higher metadata - evaluation, optimization and curation
The most valuable metadata (but also the most time-consuming to generate) is higher metadata. This includes the higher-touch information you generate when you rate for quality, assign keywords, optimize parametrically, or curate images into selected groups. This information typically takes longer to assign because it is part of a more complex evaluation process. In later sections, we’ll take a closer look at these higher levels of metadata information.
The most important images in a collection will probably have a lot of higher metadata. You’re more likely to work hard on the rendering settings, for example, and may even need to create multiple versions (color for this usage, black-and-white for that). And these images will be curated into multiple groupings, and probably exported to multiple places. We’ll want to record and centralize as much of that information as possible.